熱門文章
美國“四院院士”:人工智能將成科技的最大風口
發布時間:2019-07-29 分類:趨勢研究
2019年GMIC全球移動互聯網大會在廣州舉行,在院士AI論壇上,美國“四院院士”(國家科學院、國家醫學院、國家工程院、國家藝術與科學學院)、美國索爾克生物研究所計算神經生物學實驗室主任特倫斯?謝諾夫斯基教授發表了題為《人工智能,將成科技的最大風口》的演講。
特倫斯?謝諾夫斯基提到,過去200年,各種技術層出不窮,這樣的技術深刻影響我們生活的方方面面,人工智能未來也會影響人類的發展。
人工智能,這個名詞從1956年誕生,目標就是模仿人工智能在機器上實現,這是一個非常大的目標,但目前人類仍然遠遠沒有達到如此的目標。
人類大腦里大概有上千億個能平行工作的神經元,而電腦卻不一樣,它有處理器的,有內存,特倫斯?謝諾夫斯基表示,深度學習的靈感就是來自大腦運作機制。
特倫斯?謝諾夫斯基介紹說,深度學習能夠在計算機識別方面,可以把誤差率下降20%,這是經過很多年才有這樣的成果,雖然對于某一些圖像依然無法準確識別。(河雨)
以下為演講全文:
大家好。這是我第一次來到廣州跟大家進行演講,也是我首次參加GMIC,現在人工智能給科學發展起著推波助瀾的作用,如虎添翼。引用莎士比亞的劇目中,莎士比亞的世界是跨文化、跨國界的,今天我們討論的也是非常普適的內容。
首先我們回顧一下過去250年,從工業革命發展之初,我們從英國的工業革命興起,蒸汽機的發明增強了人類使用動能的能力,一個蒸汽機取代了一百個勞動力,大部分世界人口當時仍然在農場進行手工勞動,這樣的一些手工勞動都被蒸汽機取代了,就像美國已經高度自動化,從回到工業革命的時候蒸汽機的發明也是如此,大程度替代了很多人工勞動力,工業革命也帶來人口遷移,從鄉村轉移到城鎮,工業革命對于社會帶來極深遠的影響,過去200年可以看到,這樣一些工業革命、科學技術大程度的使用,各種技術層出不窮,這樣的技術深刻影響我們生活的方方面面。
當然也有不少缺陷,幾十年來,比如說工業革命時期的倫敦,有著大量的霧霾、煙塵,因為使用了以煤為驅動的蒸汽機導致的,而且在煤廠工作的煤炭工也飽受呼吸疾病的折磨,這是技術帶來便利的同時要面臨的挑戰,怎么在進行空氣治理,減少呼吸疾病,是一大挑戰。

技術發展的同時,也需要處理技術帶來的后果,現在我們面臨的技術人工智能也不例外,大家聽到的很多熱點科技詞語,我給大家簡單介紹一下,人工智能,這個名詞從1956年誕生,目標就是模仿人工智能在機器上實現,這是一個非常大的目標。我們現在仍然遠遠沒有達到如此的目標,人工智能范疇內,其中一個子范疇快速增長,下一位演講嘉賓會給大家細述機器學習,機器學習是以另一種方向發展人工智能,過去是編程,你能編程說明你已經有了這樣一個領域的知識去解決這個問題,而且解決問題的形式是通過編程,所以你能編程已經是這個領域的專家。
機器學習路徑是不一樣的,我們通過大量收集數據,通過機器進行學習,利用數據結構化進行學習,比如說學習一些圖像對象、語言、詞語序列等等,在機器學習范疇,又有另一個方法學,就是特定算法,是受到大腦啟發觸動的一個方向,我們大腦是非常復雜的一個設備,收集信息,有數千億的腦神經元,將信息傳遞,比如說在場這么多人,通過上千億腦神經元大腦進行信息處理,再將信息傳遞給在座各位。我們目前仍然不了解大腦內部運作,稍后給大家詳解這一塊的內容,但是我想說深度學習的靈感就是來自大腦運作機制。
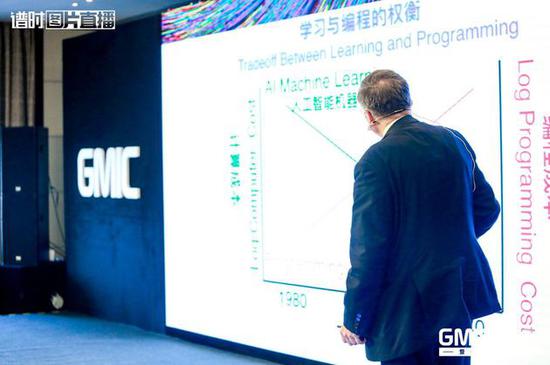
學習與編程的權衡,紅線是編程線,如果要雇一個程序員給你解決問題,這個成本是逐年增加的,1980到2040年成本是逐年增加的,編程員是很貴的,而且需要的是專家級編程員。所以相對來說,從發展開始,我們的機器學習,從上世紀80年代開始,成本非常高,電腦非常貴,但是現在人工智能、機器學習成本不斷向下,2012年機器學習算法跟編程成本大致相同,從2012年開始就逐年下降,我們使用不同的數據組,不需要完全熟悉了解這個領域的知識,不需要完全了解這個對象,但是如果獲得大量實例數據,我們機器可以通過特定的學習算法不斷解決困難,我們使用神經網絡處理系統在30年前就提出這樣的理論,就是神經網絡模式。
腦神經網絡可以有效處理復雜的數據組,也可以有能力處理上億的圖像數據,我相信在座各位對于阿爾法狗大戰是非常熟悉的,2017年打敗了柯潔世界圍棋冠軍,當時震驚時間,不僅僅因為打敗世界圍棋冠軍這么復雜的運動,同時人類還有很大的共鳴,認為機器打敗人類,超越人類了。
之前在阿爾法狗打敗世界冠軍前,認為機器可以學得很好,但是仍然不能打敗人類。我們用柯潔說的話,去年跟阿爾法狗對話,覺得它的下棋方式非常接近人類,今天已經像圍棋之神一樣在下棋,它每一步下棋的章法非常創新,是之前棋盤沒有出現過的,非常創新,如果是人,我們稱之為圍棋天才。因為是通過人工智能,阿爾法狗出現創新下棋之舉,所以也可以看到通過AI機器學習,機器也可以實現超神一般的創新。
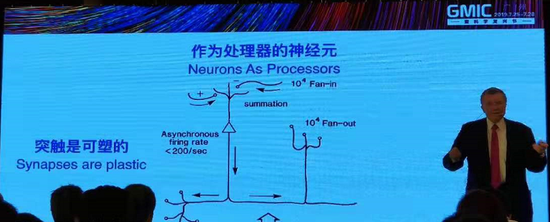
人類大腦機制,非常簡單的一個版本,大腦里有很多神經元,大概上千億的,它們是平行工作的,這和數字化電腦不一樣,因為電腦是有處理器的,是有內存的,而且這兩個硬件都有瓶頸。記憶實際上是在神經元之間的連接,也就是突觸當中存在,實際上十的十次方的神經元有十個十次方個連接,而且大腦里突觸數量非常巨大,也就大腦內存是很巨大的??梢詢Υ娣浅6嗟囊恍祿?,這是大腦的好處,問題是人腦是毫秒級傳輸速度,所以和電腦比慢很多,因為在自然中,我沒有這么多處理層,而且電腦計算速度更快,實際上我們居住的世界就是毫秒級的世界,不需要這么快的速度,我們在大腦中的信息傳遞是非常復雜的過程,還有就信息的儲存、處理等等,讓我們解決非常多的問題,這才是非常關鍵的。
還有一些挑戰,比如說有很多神經元,有突觸等等,最終是圍繞著中樞神經系統,這是最重要的一個器官。我們要知道某一個連接的改變是否會改變信息的輸入和輸出,如果把這個連接改變了,就會受到影響,當時杰弗里和我一起,得出神經算法,也就是怎么樣才能讓突觸處理正確的神經傳遞,幾乎所有的科學家和工程師在這之前覺得這是不可能的,我想告訴一些年輕人,你不要相信專家說的話,因為很多專家總是知道這個事情不能做,但是他不知道這個事情可以做成的方法。所以我們發明了玻爾茲曼機,現在在網絡神經學習中還在使用。

深度學習網絡是怎樣的?這里有各種各樣的信息數據,圖片、DAN信息等等,這邊是輸出,可能要對疾病進行診斷,各種各樣的輸入對于醫生來說,看了就可以得出診斷,每一個信息點就是神經節點,最希望有一個架構師能夠讓這些信息一層層傳遞到輸出端,可以有效的診斷這是什么疾病,比如說幫助病人治病,我們需要大量的病歷輸入才可以做到這一點。而且必須從已經確診的病人那里獲得信息,這才是有效的輸入。機器不是說要去記住這些東西,要將其泛化,因為不同人給出的輸入不一樣,人腦可以進行非常好的泛化,這是我們希望可以讓機器做的事情。

楊立昆是一個架構師,而且受到了視覺系統的啟發,大概在上世紀60、70年代的時候,已經有一些生物學家學習了人的視覺系統,所以我們知道在人腦當中,信息是如何流動的,他們來研究了猴子的架構,因為人與猴子有一定的相似性。他們就是卷積神經網絡的算法,他們設計了卷機神經網絡算法,這邊輸入信息,將圖像和神經元網絡進行結合,傳輸后進行輸出,這實際上有猴子的大腦,有一層層的神經輸入架構,最上面的是猴子的大腦皮層最上端,一、二、三層等等輸入,要怎么樣大腦才能解決視覺輸入的方法?楊立昆他們設計多層架構,使用早期的卷積神經網絡,最終他們就有了識別物體的功能,還有就是網絡中的單元,模仿人的大腦,而且有閾值,如果低于這個閾值沒有輸出,高于這個閾值才有。之后他們也進行了一系列的實驗,進行了很多技術上的工作。

2012年的時候,這是ImageNet比賽,是一個深度學習應用,這個網絡里面有概率分布,最高的概率 Mite是老鼠,我可能猜不出是蟲,可能以為是蜘蛛。這是它猜對了,這是一個小型摩托,后面猜對了是豹,上面都是猜對了的,圖像可以很好的識別出來。下面這些就是沒有猜對的圖片,這是敞篷車,有人說這是散熱器的罩,問另一個人,就說這是敞篷車,不同人看到的是不同面。第三幅圖識別出是櫻桃,實際上上面是狗,最后是madagascar貓,其實這并不是貓,人類識別是錯誤的,電腦識別出來是猴子。在訓練集里標簽標錯了,所以出現了一些錯誤,但是實際上在性能級別上,深度學習能夠在計算機識別方面,把誤差率下降20%,如果能夠下降這么多,已經非常厲害了,而且經過很多年才有這成果,對于某一些圖像依然無法準確識別。關鍵要進行不斷進行改善、演化。

今年圖靈獎頒給我的朋友楊立昆、約書亞?本吉奧、杰弗里?辛頓,這相當于諾貝爾級別了,算對他們在深度學習里非常大的鼓勵,而且深度學習現在成了很熱的詞,去年我寫了一本書,總結深度學習發展歷史,深度學習是怎么來的,還有學習算法是怎么來的,取得了哪一些成功,有哪一些失敗,未來將向何處去,還有偏差帶來的一些問題怎么解決等等,未來的挑戰,最近這本書翻譯為中文,已經有了中文版,就是右邊的照片《深度學習》,我的出版商代表也過來了。這本書多少錢呢?待會你們想買一本打折的可以跟她私下談。
這是我書中的一個章節,皮膚病醫生看皮膚病,到底是癌癥還只是良性的,已經治療了兩千例皮膚病醫生收集的數據,用來做訓練集,機器和16個皮膚病學家同場競技,發現網絡表現和醫生是并駕齊驅的,診斷率可以達到92%之高,只要有一臺手機,只要看到有一塊皮膚病就可以拍照,馬上可以得到診斷,不需要去看醫生,也不需要去付很多醫藥費,有誰去看過皮膚病的?去醫院看皮膚病真的很麻煩,有時候要做出診斷,需要好幾個星期,甚至幾個月時間,這樣往往讓病人苦不堪言,這是2017年寫的,2018年出版的,現在我們看到有幾個例子,這個看起來好可怕,實際上這是良性的,有一個看起來好像沒有什么事卻是惡性的,所以這要讓醫生來判斷。
今天我在聽一個電臺節目的時候聽到有一個公司,已經提供了這樣的服務,如果患病拍照發到他們平臺,他們AI系統就可以告訴你現在是否要就醫還是說是良性的。有一個女朋友看到她男朋友背上有一些東西,隨便拍了照片試一下,發給了這個平臺,誰知道就是惡性的,她女朋友救了男朋友一命,因為及時就診,收費才29美元。這是WAYMO自動駕駛汽車,輿論讓你感覺明天就可以做成,其實要做幾十年時間,因為有很多路況和復雜因素需要攻克和優化。
這輛汽車搭載了很多雷達和傳感器,180度傳感器不像我們人類視覺,只能看前方,它可以有180度的視角,無人駕駛汽車應用場景,現在的應用場景非常受限,我們看一下有可能的一些場景,如果我們一鍵啟車,比優步和滴滴更好,可以提高車輛使用率,如果無人駕駛汽車能夠實現,可以重新規劃停車場和停車道,大量汽車利用率增高的時候,很多車在路上跑,不需要那么多停車場了,我們現在城市遍布的停車場、停車道可以再利用,可以變成公園、自行車專道,很多公司可能要關門大吉了,就是汽車維修店和汽車保險,更重要是可以挽救很多生命,因為疲勞駕駛是導致事故死亡的很大原因。還有酒駕、醉駕這種事件很多,每年高速公路,醉酒導致死亡4萬人。
很大的便利是可以節省通行時間,尤其是出行高峰的時候,高峰時候堵車是很堵心的,如果我們使用無人駕駛汽車,都不用開車了,出行時間可以看看報紙,駕駛又完全自動安全,這樣可以降低很大的交通事故死亡率。更重要的是我們可以更進一步暢想,盜車時代會被終結。此外還有一些新的就業崗位生成,很多人說卡車司機要失業了,不會的,我們如果使用無人駕駛的卡車,也要人去控制的,他的角色轉化為安全監測崗位,這個崗位比開卡車好得多,而且更舒服,現在無人駕駛汽車仍然不能實現,因為有很多極端路況交通控制所以還不能實現,比如說卡車有一些貨物掉在路上怎么辦?所以我們還吸收有更多的訓練數據集訓練無人卡車,一旦有這種邊遠情況案例出現,比如說無人駕駛貨載卡車貨物掉路上時怎么處理,這些不是說完全沒有人監控,我們需要有人監控,機器是監控不了的,所以我們仍然需要人去監控這些無人駕駛的卡車。
還催生另一個新的產業崗位,傳感器技術供應鏈,這是一個全新的供應鏈,因為我們需要在無人駕駛車輛上邊搭載幾十億個傳感器,大量數據生成后,我們需要進行數據清理,這些都會催生很多很好的新工作崗位,這一個公司睿金科技來自中國郟縣,他們有幾千萬人專門做數據清理的公司,聽上去是挺煩燥的工作,但是比在“煤礦”上工作更好,其實是數據挖煤,這比現實中煤礦挖煤好得多。
接下來舉一個語言翻譯的例子,語言翻譯在中國幾千個語種,互相不能理解,所以我們訓練機器預計下一個字詞出現,這時候不需要分類數據,是非監督學習,這種叫做文字嵌入,如果機器能夠訓練得很好,我們期望的是學習內模通過自己的活動運算,可以了解和解構整個語義,同時要識別出大寫的專有名詞,非常有趣。比如說俄羅斯莫斯科這是對應關系,這是一個項量,將這個項量依附于德國,德國對應柏林,這個網絡沒有任何監督,就可以發現城市首都的關系,還有就是地理位置的關系,這在之前語言學領域從來沒有做過,機器學習打開了整個語言學新的理論。
此外,我們機器從翻譯上可以做時域序列解讀,從底層慢慢學習,可以解讀時態,還有語義強度、語氣強度,還有增強機器工作記憶,句頭首詞到句末最后一個詞都可以分析?,F在谷歌翻譯軟件,單字單詞翻譯并不完美,我不想讓大家有誤解,認為這個網絡已經可以理解句子的,不是的,但是比傳統的翻譯好多了,之前是字對字的硬設,這是行不通的,現在的翻譯軟件某一些語義是可以理解的,聽上去翻譯出來的中文或者英文,還是非常的奇怪,但是語義是通的。
我在我的智能手機上有一個翻譯軟件,是谷歌翻譯APP,我相信在座各位也有自己的翻譯軟件APP,我用它可以使用日文、中文字詞,可以翻譯為英文,我已經用了很多次了,語音識別可以將中文的語音翻譯為英文語音,這在某一種程度已經可以實現了。人類語種翻譯是變的,比如說有一個非常有趣的句子:我們的意志力精神,反映我們的意志之力。這是從俄語翻譯為英文后反對離題萬里,所以我們翻譯最重要是語義翻譯、句義翻譯,20世紀語言學主要領域主要是詞法上做很多研究,其實語言最重要的就是語義理解、語義解構,詞與詞的關系,這些詞組排列完后是怎樣的意思,這是語義?,F在人工智能已經往這個方向深化。
人工智能驅動的翻譯技術有多么的神奇,這是我們取得的另一個進展,這是語言網絡,有三個語種—英韓日,從英語翻譯為韓語、日語都做了實驗,但是還沒有韓語翻譯為日語,有英翻韓、英翻日,但是沒有韓翻日,我們做的這個實驗已經做了英翻韓、英翻日,能不能韓翻日,某種程度上可以,說明機器可以學習了,在一定程度上通過學習,可以韓翻日,也就是說你的訓練更多,語言組越多,訓練得越好,網絡就可以更加相通,機器的翻譯就能夠學習得更好。所以我們這種語言學網絡,可以給予我們更多的洞見,可以讓我們更加理解各語種之間的轉化和翻譯機理。我們大腦在運算的時候,總是需要大腦海馬體和皮層運作,我給大家分享一個概念,就是強化學習,怎么樣通過增強學習達成目標,這個模式就是阿爾法狗怎么打敗柯潔的秘密。

我再分享一點,最近在無監督學習中的一大突破,前提是需要大量數據組,我們把網絡里面輸入了很多名人圖像,很多都是西方人,為什么看起來都像名人呢?這個網絡很厲害,它實際上可以生成關于名人的新的圖像,之前是沒有存在過的,所有的圖片都是不存在的,只是給出的案例中依據自動生成的,而且可以生成很多圖像,但是這些都不是真實的人,都不是真實存在的,還可以不斷的繼續下去,所以這個例子就向我們展示了未來,生成性的網絡,就像我們的大腦,我們大腦也會不斷生成信息,我們坐那里,就會有各種各樣的想法出現。
現在我們到哪一步了?還是在初期,就好象是萊特兄弟做了第一臺飛機的時候,離噴氣式飛機還有很長一段路要走,萊特兄弟幾年前出了一本關于他們的傳記,很好看,里面寫著說萊特兄弟研究鳥很久,因為鳥可以飛過千山萬水,不用經常拍動翅膀,而且他們對于空氣動力學非常感興趣,還建立了風動,所以萊特兄弟本質上就是工程師,我們從自然當中可以學到很多東西,萊特兄弟研究了自然,研究了鳥,然后他們發現大自然是這樣解決問題的,而且要解決這些困難的問題并不難,大自然已經會了,大自然中已經蘊含著解開這些奧秘的鑰匙了。我們還處于很早期的階段,但是也在不斷的進步,去年12月的時候,在蒙特利爾有100萬人參加了會議,接下來12月我們覺得應該會有4萬人來參加這個大會,我相信2020年來參加這個會議的人會更多。
非常感謝各位的參與,感謝各位的聆聽,我們還處于人工智能早期階段,還有很多問題需要解決,我們也看到了非常令人興奮的成就和成果,恐怕有一些問題要花很多年才能解決,但是實際上有一些問題像自動駕駛汽車不能說以年來解決問題的,而是以十幾年時間來計算,有時候需要幾代人努力,但是回顧一下工業革命,這不是一夜之間發生的,而是經過幾代人努力才實現的,所以各位的孩子就會從你們手中接過這個成果,從充滿AI的世界中長大。那時候就像大家看到飛機一樣,人工智能會非常的普遍,謝謝各位。


